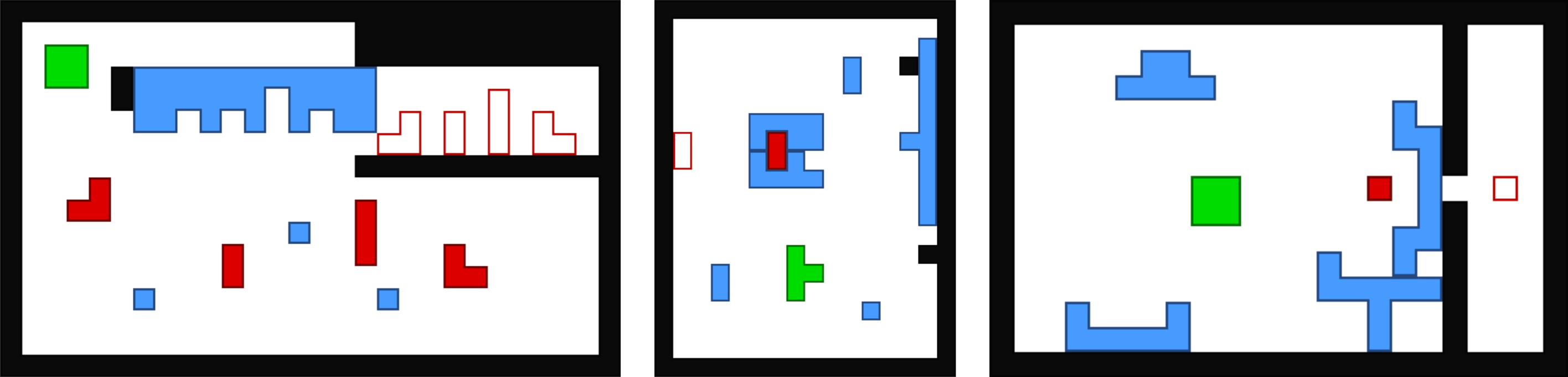
PushWorld is a novel grid-world environment designed to test planning and reasoning
with physical tools and movable obstacles. While recent advances in artificial intelligence have achieved human-level performance in environments like Starcraft and Go, many physical reasoning tasks remain challenging for computers. The PushWorld benchmark is a collection of puzzles that emphasize this challenge.PushWorld is available as an OpenAI Gym environment and in PDDL format in Github. The environment is suitable for research in classical planning, reinforcement learning, combined task and motion planning, and cognitive science.
Play PushWorld
Here you can play all puzzles in the PushWorld benchmark. All puzzles are solvable.
Select a Puzzle Difficulty
Level 1
Level 2
Level 3
Level 4
Level 1 Puzzles
Level 2 Puzzles
Level 3 Puzzles
Level 4 Puzzles
Puzzle Name
Use the arrow keys to push the red shapes into their outlines. Use the
Undo
and
Reset
buttons above to retry a puzzle.
Solved!
PushWorld vs. Related Environments
Solving PushWorld puzzles requires many skills, including:
Path Planning: Finding a collision-free path to move an object from one position to another, considering walls and object shapes.
Manipulation Planning: Exploring alternative ways to push an object along a desired path. Some puzzles require the agent to preemptively position itself so that it can move from pushing in one direction to pushing in a different direction in the future.
Moving Obstacles: The agent must decide between finding a path around an obstacle or moving the obstacle out of the way. Some obstacles introduce choices in which freeing one path blocks another, and choices can be irreversible. Obstacles can also be "parasitic": once pushed against an object, the agent can never separate the obstacle from the object.
Using Tools: To move an object into a desired position, the agent may need to use one or more objects as tools to indirectly push the target object: the agent pushes a tool object, which simultaneously pushes the target or another tool. In some puzzles the agent must assemble a tool by pushing multiple objects together.
Prioritizing Multiple Goals: Moving an object into its goal position too soon may prevent achieving another goal, and some puzzles require achieving multiple goals simultaneously by preemptively arranging objects and pushing them all at once.
Several existing environments have dynamics similar to PushWorld: Sokoban, sliding block puzzles, and grid-based path planning. However, none of these environments require all of the skills above.
Sokoban
Sliding Block Puzzles
Grid-Based Path Planning
PushWorld
Varied Object Shapes
X
✔
✔
✔
Path Planning
✔
X
✔
✔
Manipulation Planning
X
X
X
✔
Movable Obstacles
✔
✔
X
✔
Tool Use
X
X
X
✔
Multiple Goals
✔
✔
X
✔
Evaluation: Classical Planners
We compared the following classical planning algorithms on the set of puzzles above:
Fast Forward is a seminal planning algorithm that relies on a delete relaxation heuristic.
Fast Downward introduced domain transition graphs and the causal graph heuristic (winner of IPC 2004 classical track).
LAMA introduced the landmark heuristic (winner of IPC 2008 sequential satisficing track).
Best-First Width Search (BFWS) uses the novelty heuristic, which prioritizes states that contain novel substates (winner of IPC 2018 agile track).
Fast Downward Stone Soup (FDSS) is a portfolio of planners (winner of IPC 2018 satisficing track).
Saarplan is another portfolio of planners (runner-up of IPC 2018 agile track).
RGD is a greedy best-first search with the recursive graph distance heuristic introduced in the PushWorld paper.
Novelty+RGD is a greedy best-first search with a lexicographic heuristic that combines the novelty heuristic with the RGD heuristic, prioritizing novelty.
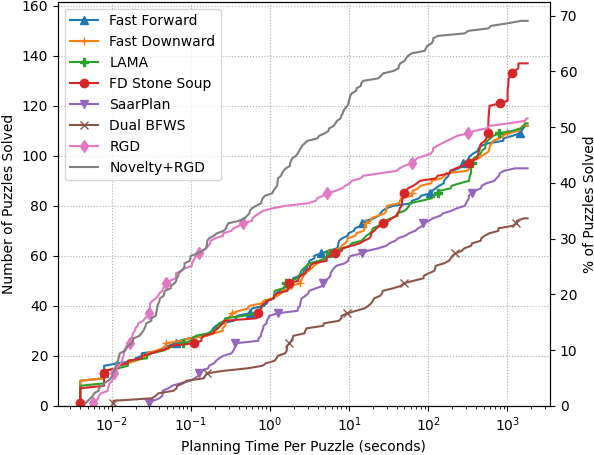
The plot below shows how many puzzles each planner solves within a given time per puzzle. Novelty+RGD solves the most puzzles (69.1%) within 30 minutes per puzzle, followed by FDSS (61.4%). Notably, Novelty+RGD solves as many puzzles in 45 seconds as FDSS solves in 30 minutes, which amounts to a 40x speed improvement.
Evaluation: Model-Free Deep Reinforcement Learning
We selected two deep reinforcement learning (RL) algorithms to evaluate on PushWorld: Deep Q-Network (DQN), an off-policy, value-based algorithm, and Proximal Policy Optimization (PPO), an on-policy, policy-gradient algorithm. We chose these algorithms because they are widely used, easy to implement, and have shown competitive performance on diverse and challenging tasks like Atari and continuous robotic control.We trained both PPO and DQN on all Level 1 puzzles and measured the percentage of Level 1 puzzles they could solve. DQN converged to solving less than 1% of the puzzles, and PPO converged to solving 6% of the puzzles. We believe this low performance is in part due to the low probability of solving most Level 1 puzzles with the initial policy, resulting in sparse positive rewards.To address the sparse reward problem, we programmatically generated a collection of Level 0 puzzle sets that are no larger than 10x10 cells. The PushWorld paper provides details of these puzzle sets, and the table below shows the percentage of training and testing puzzles solved by PPO and DQN. Overall, PPO outperforms DQN but shows signs of overfitting.
PPO
DQN
Level 0 Puzzle Set
Train
Test
Train
Test
Base
88.5%
40.4%
24.9%
19.5%
Larger Puzzle Sizes
93.2%
71.5%
61.2%
61.8%
More Walls
77.9%
23.3%
18.5%
13.1%
More Obstacles
64.7%
21.4%
17.6%
13.1%
More Shapes
74.5%
24.2%
23.9%
17.1%
Multiple Goals
5.3%
1.1%
0.9%
0.2%
All
21.2%
5.7%
11.4%
10.1%
Next Steps
PushWorld presents a challenge for both classical planners and model-free RL algorithms. After playing the benchmark puzzles yourself, we hope you were able to solve >95% of the puzzles in far less than 30 minutes per puzzle, demonstrating that current artificial intelligence algorithms are not yet human-level in PushWorld. We hope you are inspired to develop new algorithms that are closer to human-level performance.